My github is a graveyard of unfinished projects. So, when a new idea hit me, I didn’t even bother opening my laptop. Why would this time be different? Two months later, I finally picked it up (mostly to shut my brain up) and built Visual Minipro.
What is it?
Visual Minipro is the missing MacOs app for XGecu EEPROM programmers. I built it for retro-computing enthusiasts (like myself), automotive technicians, and electronic hobbyists who want to be able to use their XGecu programmers on Mac in an easy and intuitive way.
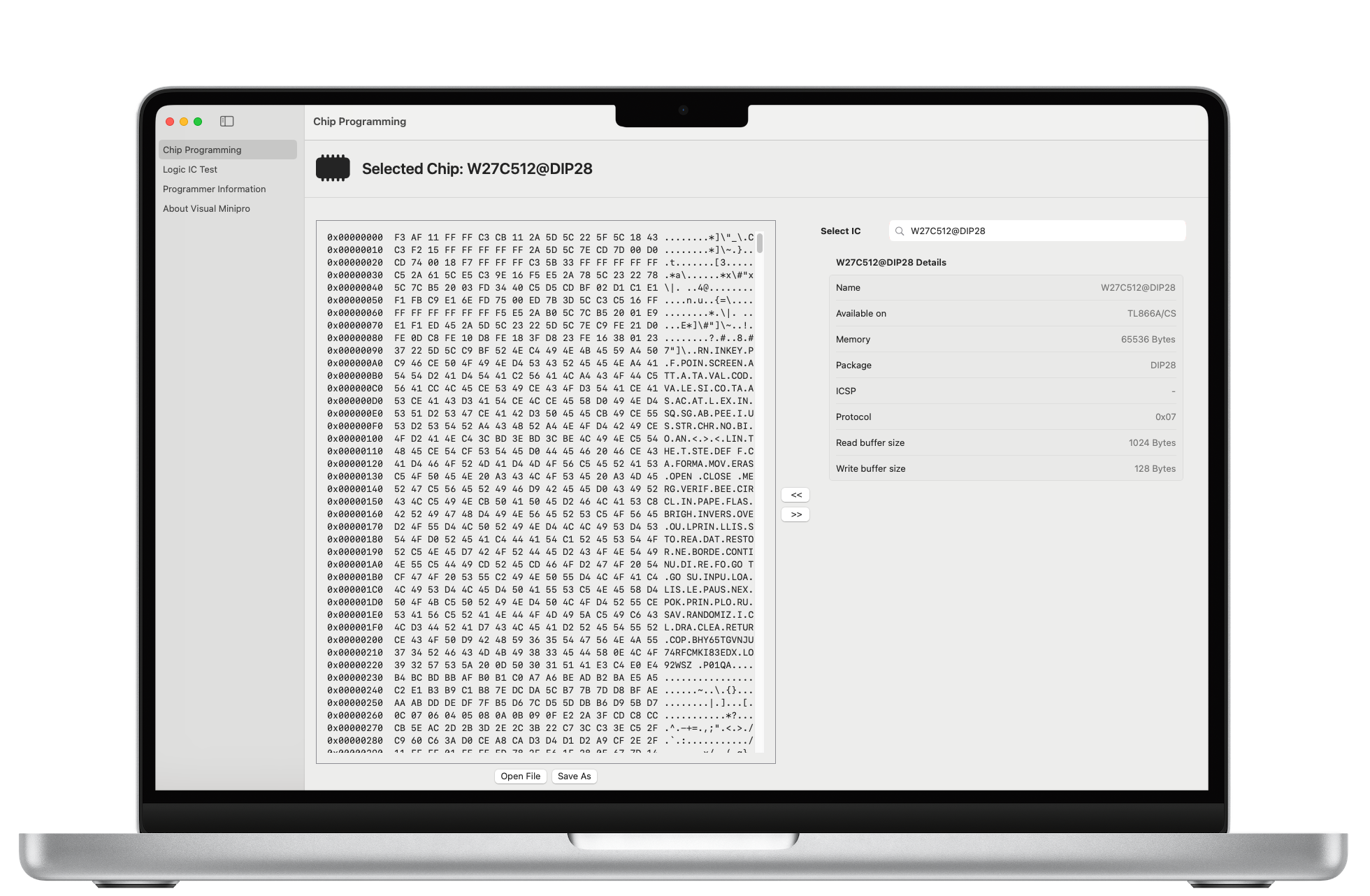
Why I built it
A while ago, I built a replica of a computer that’s older than internet (ZX Spectrum). Because the kit didn’t include the ROM (due to copyright), I essentially built a brick. I hastily ordered a T48 XGecu programmer to bring my new computer to life, but couldn’t make it work with my Mac.
I hoped to find a solution on the official website and was welcomed by this:
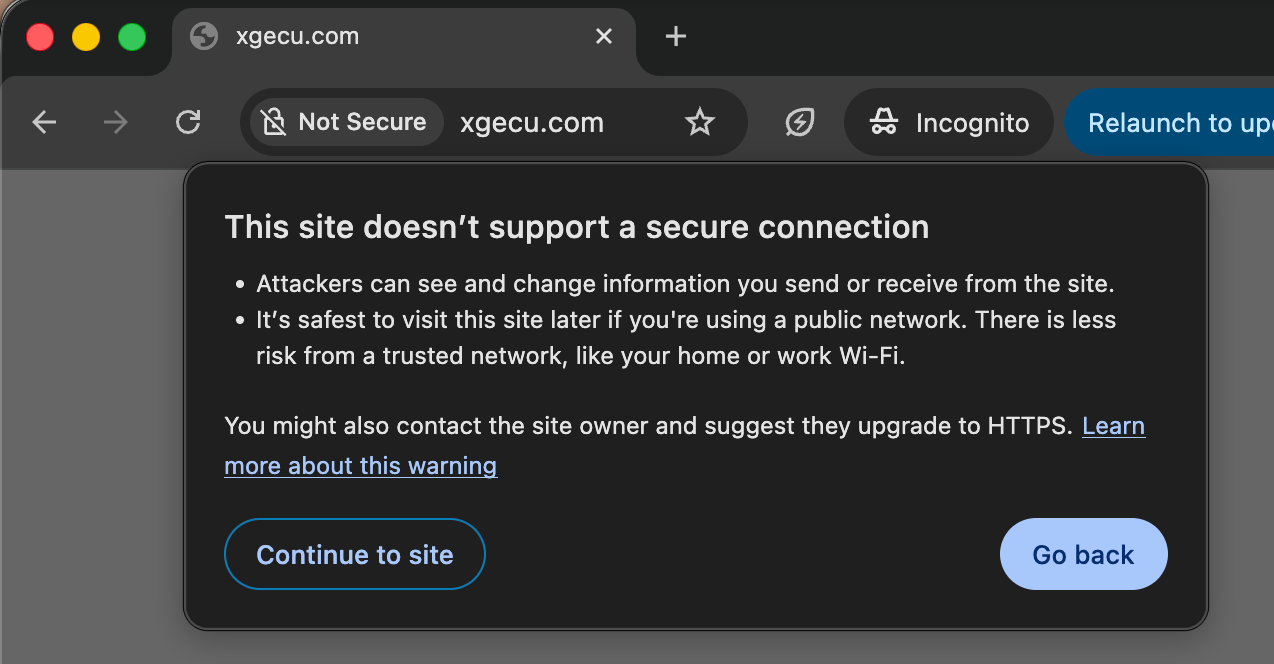
Despite a few red flags, I downloaded the software for my programmer:

It was a .RAR file and I knew what it meant – they only supported Windows!
As a long-time Mac user, I was disappointed. The prospect of installing Parallels only to use the programmer wasn’t appealing. Fortunately, I came across minipro – an open source, command line tool for handling XGecu programmers.
The tool did what it advertised and unblocked my project. However, the version available on brew was outdated and to get something newer, I had to compile it myself.
Parameters were another thing I fought with. I could not remember them and had to refer to man pages dozens of times.
This experience enlightened me – I couldn’t be the only Mac person in the world who wanted to use their XGecu programmer without time-wasting side quests.
The finish line that almost wasn’t
Starting the project took a couple months but finishing it almost didn’t happen.
Visual Minipro wraps the minipro tool. Building an MVP was relatively quick because minipro did all the heavy lifting. But the App Store doesn’t accept MVPs. All apps need to meet certain requirements to be accepted. Due to the app structure, satisfying these requirements was harder than I expected:
- bundling – App Store apps are sandboxed and can’t access files outside of the sandbox. Ensuring that external tools and dynamic libraries can be loaded correctly is tricky.
- signing – Apple requires all App Store apps to be signed. XCode handles signing the application but I couldn’t find a way to make it sign dependencies like mine.
- permissions – the app got rejected by App Store twice due to permissions. One claim was valid (I thought I needed a permission while I didn’t) but the other was not and required a little back-and-forth to convince them that apps handling USB devices require the USB permission
- universal binaries – the first version of the app only worked on Apple Silicon. I decided to add support for Intel based Macs after a few people asked for it. Building universal binaries for dependencies turned out to be a bit of work because their build scripts only supported the current architecture. Testing was even harder – I only had a no longer supported 2015 MacBook Pro where many newer SwiftUI features weren’t supported.
Solving these problems took enough of my time that I almost started working on a new idea. But I persevered and learned (or re-learned) a few things:
- shipping software is hard
- the last 10% takes more time than the first 90%
- XCode works reasonably well for main scenarios but things get hairy when you get off the beaten path. Fortunately, Apple has command line tools accompanied by posts from around 2013 that explain how to deal with these scenarios (reading these posts is a pain)
- the App Store app review is not as bad
Memorable moments
First Sale
My first sale surprised me. Not because it came so quickly, but because I learned about it from an unexpected channel after I almost forgot about Visual Minipro.
In the beginning, I was checking my stats daily hoping to see some movement. Looking at zero sold copies got boring and then even depressing, so I stopped. A few weeks later, I received a bug report claiming the app didn’t work. After a short investigation, I concluded the person was building the app from sources and didn’t correctly bundle minipro. I recommended getting the app from the App Store where I knew all components were bundled correctly. To my surprise, they said they did use the version from the App Store.
I checked the App Store dashboard – it did show one copy sold!
(and the problem turned out to be an environmental issue – the app worked fine on a different Mac)
Liquid Glass fiasco
In late December 2025 I noticed an increase in refund requests from App Store but couldn’t figure out the reason. Then, in January, I installed macOS 26 (Tahoe) on my Mac and it became obvious. Liquid Glass made my app look so bad that it became unusable – even I felt lost. I dropped everything and submitted a new, fixed version of the app the same evening.
App Store Small Business program
Seeing Apple taking 30% of $30 I made selling a couple copies of my app made me sad. Finding out they have a program that reduces their commission to 15% for small developers if you apply, made angry.
I heard about Apple introducing the App Store Small Business program as a side effect of the Epic Games v. Apple lawsuit. But it was in 2020 and I had long forgotten about it. I was reminded about the program by a random reddit post. I applied and forgot about it again because I didn’t hear back. It took Apple more than three weeks to process my application and confirm I was eligible.
Show me the money!
Visual Minipro is a niche app. I won’t claim it makes thousands of dollars in ARR or that it will allow me to retire early. It does, however, make enough to cover the cost of my domains, hosting and dev subscriptions.
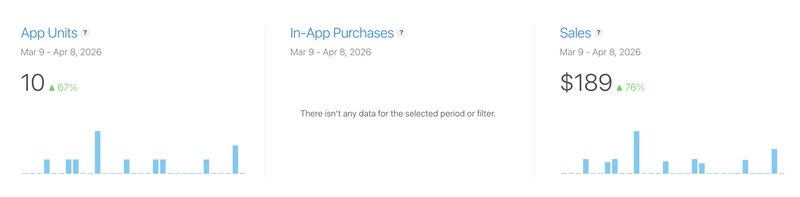
Why I think the app sells?
I will be brutally honest – I found a few alternatives to Visual Minipro and they did look better. But all of them had the same fundamental problem: friction.
Assuming you even find one of these apps, the first step is to compile them. If you want to keep it up-to-date (if it’s still maintained) – you will have to periodically check for new releases and recompile them. As soon as get a new laptop, you guessed it right: you will have to compile it again, but first you need to find and install all tools and dependencies.
And, unless you read all the code carefully, you’ll never know what you’re compiling.
Getting an app from the App store is much more convenient and almost risk-free. No time wasted on figuring out dependencies and make files. Automatic updates. Clearly stated permissions. In the worst case, if you don’t like the app, you can request a refund.
What kept me going?
I almost gave up working on Visual Minipro several times. The two main reasons I didn’t:
- Scratching your own itch – I wanted an app like this for myself. I find it useful, and even if no one buys it, I will keep using it.
- Product/market fit – Visual Minipro is filling a real gap in the market. The XGecu programmers are quite popular and I was surprised they only supported Windows.
What’s next?
I am maintaining the Visual Minipro app by fixing issues and adding new features. These updates are primarily driven by user feedback and my own observations. I am also trying new ideas because this project taught me I am capable of finishing them.










