In the last few months, I have published more than a dozen posts on dev.to. Soon after I started, I realized that the analytics provided out-of-the-box was missing some features. One that I have been missing the most is the ability to see a daily breakdown of read posts.
Fortunately, the UI is not the only way to access stats. They are also available via the DEV Community API (Dev.to API). I decided to spend a few hours this weekend to see what it would take to use the Dev.to API to build the feature I was missing the most. I wrote this post to share my learnings.
Project overview
For my project, I decided to build a JavaScript web application with the Express framework and EJS templates. I did this because I wanted a dashboard with some nice-looking graphs. After I started, I realized that building a dashboard would be a waste of time because printing the stats would yield almost the same result (i.e. I could ship without it). In retrospect, my prototype could have been just a command-line application, which would have halved my effort.
DEV Community API crash course
I learned most about what I needed by investigating how the DEV dashboard worked. Using Chrome Developer Tools, I discovered two endpoints that were key to achieving my goal:
- retrieving a list of articles
- getting historical stats for a post
Both endpoints require authorization. API authorization mandates setting the api-key header in the HTTP requests. To get your API Key, go to Settings, click on Extensions on the left side, and scroll to the DEV Community API Keys at the bottom of the page. Here, you can see your active keys or generate a new key:

Once you have your API key, you can send API requests using fetch as follows:
function initiateDevToRequest(url, apiKey) {
return fetch(url, {
headers: {
"api-key": apiKey,
},
});
}
Retrieving posts
To retrieve a list of published articles, we need to send an HTTP Request to the articles endpoint:
https://dev.to/api/articles/me/published
A successful response is a JSON payload that contains details about published articles, including their IDs and titles.
Side note: there is a version of this API that does not require authorization. You request a list of articles for any user with the following URL: https://dev.to/api/articles?username=moozzyk
Fetching stats
To fetch stats, we need to send a request like this:
https://dev.to/api/analytics/historical?start=2024-02-10&article_id=1769817
The start parameter indicates the start date, while the article_id defines which article we want the stats for.
Productivity tip
You can test APIs requested with the GET method by pasting the URL directly in the browser, as browser authorization does not rely on the api-key header.
<rant>
I found the DEV Community API situation quite confusing. I was pointed to Forem by a web search and initially did not understand the connection between dev.to and Forem. In addition, the Forem’s API page contradicts itself about which API version to use. Finally, it turned out that API documentation does not include the endpoints I use in my project (but hey, they work!).
</rant>
Implementation
Once I figured out the APIs, I concluded that I can implement my idea in three steps:
- send a request to the articles endpoint to retrieve the list of articles
- for each article, send a request to the analytics endpoint to fetch the stats
- group stats by date and show them to the user
Throttling
In my first implementation, I created a fetch request for each article and used Promise.all to send all of them in parallel. I knew it was generally not a brilliant idea because Promise.all does not allow to limit concurrency, but I hoped it would work for my case as I had fewer than 20 articles. I was wrong. With this approach, I only got stats for at most two articles. All other requests were rejected with the 429: Too many requests errors. My requests were throttled even after I changed my code to send one request at a time. To fix this problem, I added delay between requests like this:
const statResponses = [];
// Poor man's rate limiting to avoid 429: Too Many Requests
for (const article of articles) {
const resp =
await initiateArticleStatRequest(article, startDate);
statResponses.push(resp.ok ? await resp.json() : {});
await new Promise((resolve) => setTimeout(resolve, 200));
}
This is not great but works good enough for a handful of articles.
Side note: I noticed that even the UI Dashboard fails to load quite frequently due to throttling
Result
Here is the result – stats for my posts for the past seven days, broken by day:
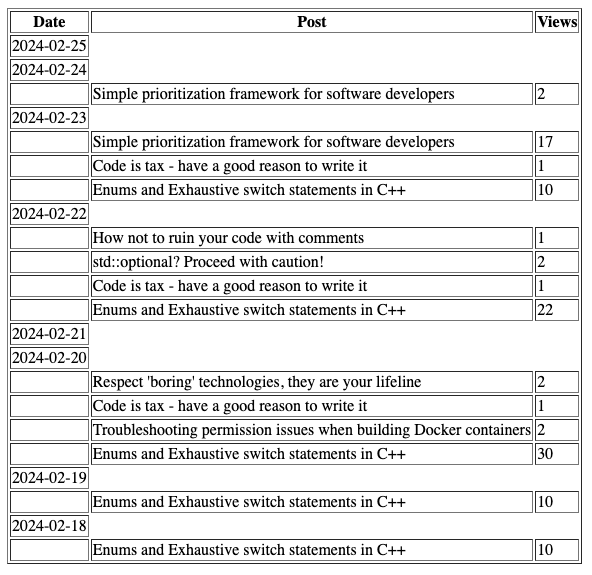
It is not pretty, but it does have all the information I wanted to get.
Do It Yourself
If you want to learn more about the implementation or just try the project, the code is available on github.
Important: The app reads the API Key from the DEVTO_API_KEY environment variable. You can either set it before starting the app, or configure it in the .env file and start the app with node --env-file=.env index.js
Hopefully you found this useful. If you have any questions drop a comment below.


{kind=link}